데이터 운용
데이터 운용
운용
- 특정한 기준에 대한 정확한 기술은 측정지표(측정 대상)와 데이터 수집 방법론(측정 방법), 수집할 데이터의 양(얼마나 많은 것을 측정할 것)과 데이터 수집의 책임(측정자)를 결정하기 위해 필요함
데이터 수집
데이터 수집
- 분석에 필요한 데이터 종류, 형태, 발생 주기 등 데이터의 특성을 파악하고 정의하는 것
- 분석에 필요한 데이터 항목, 저장위치, 발생 주기, 수집 방법, 수집 기간, 속성 등을 기술함
샘플링
- 샘플 데이터 생성 및 데이터 분할 시 데이터를 추출하는 방법용
- 샘플링 유의사항
- 대표성 : 전체 데이터를 대표하는 샘플인가
- 안정성 : 안정된 프로세스에서 수집된 데이터 샘플인가
- 랜덤성 : 특별한 경향이나 패턴 없이 무작위로 선택했는가
- 일관성 : 동일한 방법이 일관되게 적용되었는가
- 무작위 샘플링 : Random Sampling
- 무작위로 추출 => 각 자료의 선택 확률은 동일
- 층별화 샘플링 : Stratified Sampling
- 유사 특성별 층별화하고 무작위로 자료 선택 =>선택 비율은 집단의 비율 반영
- 모집단을 몇 개의 그룹으로 나누어 각 그룹에서 무작위로 n개씩 추출
- 계통 샘플링 : Systematic Sampling
- 매 k번째 자료 선택 => 일정 간격마다 데이터를 추출
- 군집 샘플링 : Cluster Sampling
- 모집단을 여러 집단으로 나누고 군집을 선정하고 선정된 군집 내 전체 데이터를 사용

불균형 데이터 샘플링
- 불균형 데이터 : 분류형 목표변수의 데이터가 불균형을 이룬 경우
- 불균형 데이터 표본추출 문제 : 일반적으로 관측수가 많은 범주의 데이터가 지배적인 영향을 미쳐 학습 모델의 성능 저하
- 불량 10개, 양품 990개인 데이터를 모두 양품으로 분류할 확률이 99%라는 문제 발생
- 불균형 데이터 해결방법
- Oversampling : 소수의 데이터를 줄이는 방법, 적은 레이블을 가진 데이터 세트를 많은 레이블을 가진 데이터 세트 수준으로 증식하여 학습에 충분한 데이터를 확보하는 기법 => 일반적으로 Undersampling보다 성능이 좋아 주로 사용
- SMOTE : 적은 데이터 셋에서 개별 데이터들에 KNN 적용 후, 샘플과 이웃간 연결하는 segment 상에 랜덤하게 데이터 생성
- BLSMOTE : borderline에 있는 데이터가 불균형에 영향을 미친다고 판단해 borderline data에 대해 smote 적용
- DBSMOTE : DBSCAN cluster 생성 후 cluster 내에서 smote 적용
- Undersampling : 다수의 데이터를 줄이는 방법, 많은 레이블을 가진 데이터 세트를 적은 레이블을 가진 데이터 세트 수준으로 감소시키는 기법 => 너무 많이 제거하지 않도록 해야함
- Oversampling : 소수의 데이터를 줄이는 방법, 적은 레이블을 가진 데이터 세트를 많은 레이블을 가진 데이터 세트 수준으로 증식하여 학습에 충분한 데이터를 확보하는 기법 => 일반적으로 Undersampling보다 성능이 좋아 주로 사용


데이터 정제
데이터 정제
- 정제 : 데이터 확인을 통해 발견된 결측치나 이상치에 대한 적절한 처리를 통해 데이터 품질을 보강하는 작업
- 분석 결과의 신뢰성 향상을 위한 사전 작업
결측치
- 결측치 이해 : 데이터 값이 반드시 존재해야함에도 불구하고 누락된 데이터를 의미
- 일반적 통계 분석에서 결측치 자료(행)은 제외됨 => 분석 데이터의 양이 감소됨
- 목표 변수의 값이 누락된 경우 : 목표 변수 값을 추가 확인, 수집, 제외해야 함
- 결측치에 대한 적절한 처리를 사전에 하여 분석 결과에 대한 신뢰성 확보가 가능
- 결측치 처리
- 연속형 변수 : 평균값, 중앙값, 분포 기반, 모델에 의한 대체
- 이산형 변수 : 최빈값, 분포 기반, 모델에 의한 대체
이상치
- 데이터 값이 발생할 수 있는 범위를 벗어난 데이터를 의미
- 상자수염도표를 이용해 이상치 확인
파생 및 변환
- 분석 모델이 요구하는 조건을 만족시키기 위해 변수 값을 변환하거나 새로운 변수를 생성하는 작업
- 분석 데이터의 변수 간 특성 및 관계 확인 -> 파생 변수의 필요성 검토, 처리 -> 데이터 변환의 필요성 검토, 처리
- 분석 데이터의 변수 간 특성 및 관계 확인 : 데이터 단위 확인
- 파생 변수의 필요성 검토, 처리 : 변수의 특성 고려, 변수의 측정 단위 고려
변수의 크기 조정 필요성 검토 및 처리
- Standard Scaler : 가장 많이 사용, 평균 및 표준편차를 이용한 변환, (평균이) 이상치에 영향을 많이 받음
- Min-Max scaler : 최대 및 최소값을 이용한 변환, (최대 및 최소값이) 이상치에 영향을 많이 받음
- Robust scaler : 중앙값 이용, 가장 안정적임, 이상치에 영향을 덜 받음


데이터 수집 및 정제 - 실습
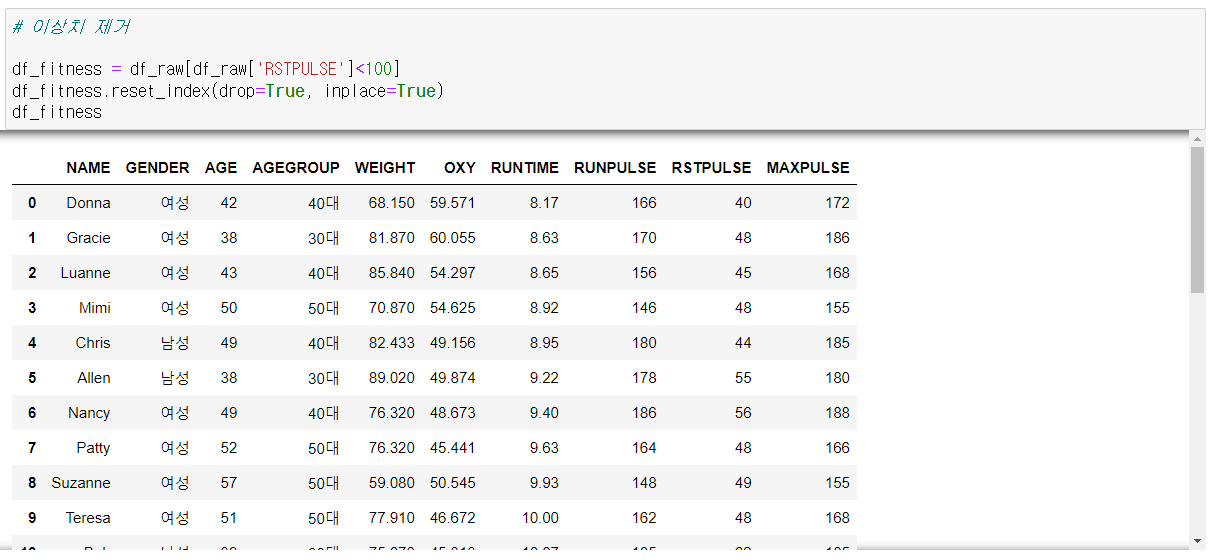
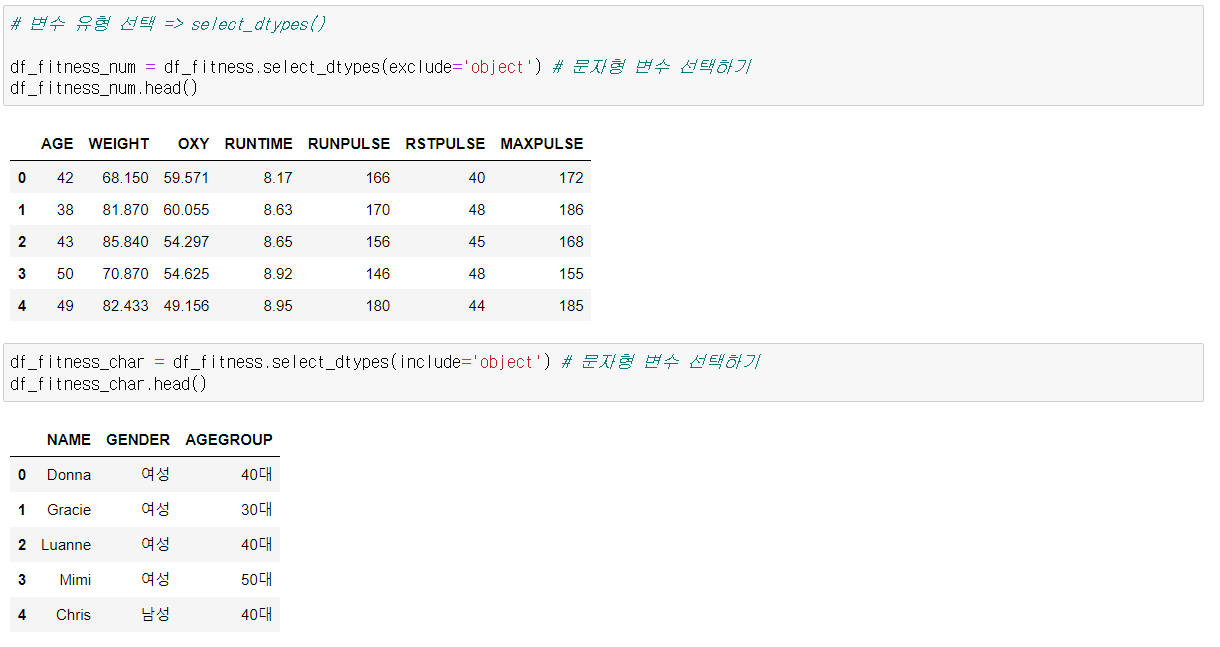
결측치 및 이상치 처리




Scaler



'Big Data' 카테고리의 다른 글
| 예측 모델 - Linear Regression/Decision Tree/Random Forest/Gradient Boosting (1) | 2022.05.23 |
|---|---|
| 탐색적 분석 - 통계 분석 (0) | 2022.05.20 |
| Big Data 분석 - 탐색적 분석(시각화) (0) | 2022.05.19 |
| Big Data 분석 - 분석 계획 (0) | 2022.05.19 |
| Big Data 분석 - Data Handling (0) | 2022.05.18 |


